More tools: Travis CI, Codacy, and Codecov
Welcome back.
After my previous post on Gource, another post on cool tools I started using with QuantLib: Travis CI, Codacy, and Codecov. All of them analyse the code and help keep it in shape, and all of them integrate seamlessly with GitHub.
Lately, if you looked at a pull request while logged in to GitHub, you might have noticed something like this at the bottom:
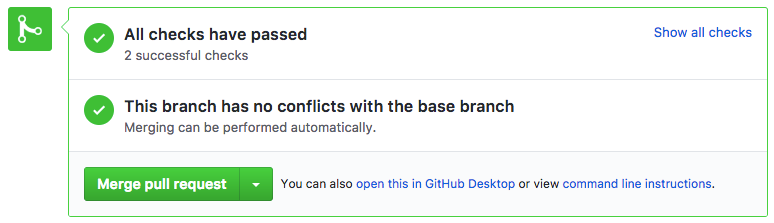
What checks? Well, the ones I added to the repository thanks to those tools. The first I added was Codacy: it’s a static analysis front-end that uses tools for a number of languages, including C++. When integrated with your GitHub repo, it analyses your master branch and any other you select in the settings and gives you a summary of possible issues with your code. Not only that; whenever a new pull request is opened, it checks whether it fixes any of those issue (good) or it adds new ones (bad). This allows you to try and set a trend towards cleanliness, or at least to avoid getting further from it.
In the case of QuantLib, we had some 400 issues; the report is public,
and you can see it
here. We
managed to fix about a quarter of them; the remaining 300-odd are
mostly about constructors which take just one argument but are not
declared as explicit. We’ll probably fix them, a few at a time.
Technically, it is a breaking change to make such a constructor
explicit, since it might cause existing code to stop compiling.
However, picking a few examples, that code would have to be something
like:
GammaDistribution f = 1.0;
TwoFactorModel model = 2;
Iceland calendar = Iceland::ICEX;
I hope you’ll agree that the first two examples should be simply taken out and shot. The third one is not very idiomatic, but might be debatable. The ones I fixed so far were allowing code like:
Handle<YieldTermStructure> forecastCurve;
Euribor6M index = forecastCurve;
which was firmly in take-out-and-shoot territory.
The next integration was with Travis CI, a continuous-integration tool. Like Codacy, it runs its magic at each commit and pull request: the magic being a script that you can specify and that builds and tests the code. The only catch: it has to run in 45 minutes, and here is where things got interesting. Building and testing QuantLib in full takes way more than that. Therefore, I had to save time where I could.
The first thing I tried was enabling ccache, since Travis supports it. However, I needed a first run to bootstrap the cache, and I couldn’t do it in one go; so I run a first version of the script building only the library, and a second (which at that point would use the cache to build the library) to include the examples and test suite into the build. I had won the first battle, but not the war, though: large changes, or Travis purging the cache after a period of inactivity, would still cause the build to go beyond the limit.
Second change: the examples used to start with
// the only header you need to use QuantLib
#include <ql/quantlib.hpp>
which was convenient to write, and was probably fine when we started
in 2000, but nowadays would bring in some 320,000 lines of code after
preprocessing. Therefore, out went the global header. Now the
examples only include the headers they need, and I advise that your
sources do the same. The line count after preprocessing went down on
average to around 100,000, and the compilation times dropped
accordingly. On my Mac, and using the -O2 optimization level, the
average example would compile in about 20 seconds before the change;
after the change, it takes between 5 and 10, with a few dropping below
5 seconds and none above 20. It adds up, now that we have 19 of them
in the source tree.
Final change: the test suite is running in between 12 and 15 minutes, which is way too much. Fortunately, Klaus Spanderen had put in place some code to measure the time taken by each test case, so I looked at the data. It turned out that more than 90% of the test suite, or about 620 out of 670, actually runs in under three minutes, with the other 50 tests accounting for the remaining 10 minutes. I added a switch to the test suite to only run that 90%, and there I was. You can see the latest pull-request checks here: they are comfortably under the 45-minutes mark, taking as little as just a few minutes if compilation hits the cache heavily.
Having these automated checks now help me detect pull requests that don’t compile or otherwise break the build, without having to check them out locally and do it myself. (Don’t fear, though: I still run the whole test suite before merging into master.) Hopefully, this will translate into more frequent releases coming your way.
A last integration is not shown, because it hasn’t made into master. I’ve added Codecov, which provides a nice web interface to the code-coverage data provided by g++ through gcov. The production of coverage data and its transfer to Codecov analysis can be added to the Travis run, but unfortunately the compilation flags that enable coverage analysis are incompatible with ccache.
Not all is lost, though. By chance, I had just read on the latest
issue of the Overload journal
an interesting article on unity builds.
The idea in short (read the article for details) is to create a file
that #includes all the .cpp files in a directory and compile it,
instead of compiling each file separately. This often results in
improved compilation times, since we’re parsing common headers just
once instead of doing it in each source file. The creation of the
aggregate files can be automated by a Makefile rule. Long story
short, I created a branch for Codecov integration, I added a switch to
./configure to enable the unity build (which might be useful in its
own right, so could go into master), and I disabled ccache and enabled
coverage information in the Travis script. The result runs in about
40 minutes. I’ll probably update the branch every once in a while to
check trends in coverage. I thought about merging it into master and
having it run at each commit, but in this case it seemed like a waste
of resources to have Travis run for 40 minutes instead of 10 or 20
each time.
Especially because those resources are given out for free. Codacy, Travis CI, Codecov, and of course GitHub (oh, by the way: I’m not affiliated with, or sponsored by, or paid to endorse any of them) are all free for open-source projects. Thanks, people. And you, dear readers: consider showing some love and using their paid versions for your code if your projects have the budget for it. It’s good for everybody if they stay alive.
Subscribe to my Substack to receive my posts in your inbox, or follow me on Twitter or LinkedIn if you want to be notified of new posts, or subscribe via RSS if you’re the tech type: the buttons for all that are in the footer. Also, I’m available for training, both online and (when possible) on-site: visit my Training page for more information.